近年のLLM(大規模言語モデル)は、単なる「確率的な単語選択」を超えた論理的思考能力を示しつつありますね。特に、「次に出現する確率の高い単語を選ぶだけでは解けない問題」を解決できるようになってきた点は注目すべきです。
現在のLLMの論理的思考能力について簡単に整理すると、以下のような特徴が挙げられます。
形式的な論理推論が可能
たとえば、数学的な推論やルールベースの論理問題では、ある程度の正確性を持って解答を導き出すことができます。これは、学習データの中に類似のパターンが多く含まれているため、正しく推論できるケースが増えてきたためです。
LLMの論理的思考を試す(1) ~簡単な経路をたどる問題~
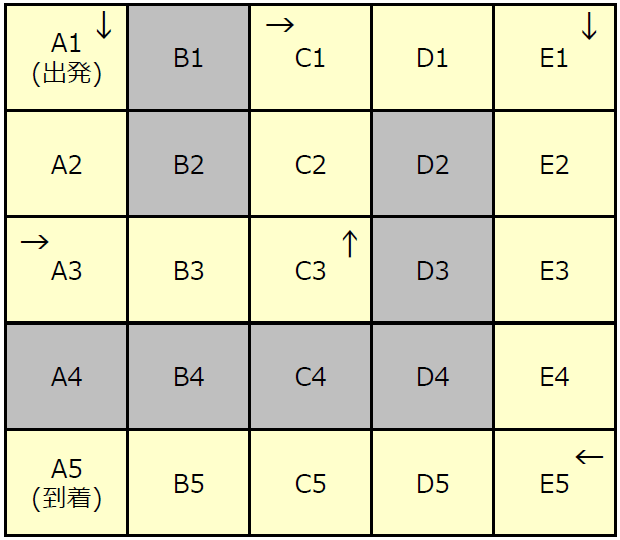
以下に、横5ブロック、縦5ブロックで表現したマップを示します。
‘■’は壁を表し、’□’は道を表しています。
マップの各ブロックはExcelのセル参照と同じです。
横軸がA,B,C,・・・、縦軸が1,2,3,・・・となっていて、例えばマップの左上のブロックは’A1’です。
このマップに対して、人間が’A1’から’A5’に辿り着くためには、どのように道を辿ればよいですか?
マップ

経路:
A1 ⇒ A2 ⇒ A3 ⇒ B3 ⇒ C3 ⇒ C2 ⇒ C1 ⇒D1 ⇒ E1 ⇒ E2 ⇒ E3 ⇒ E4 ⇒ E5 ⇒ D5 ⇒ C5 ⇒B5 ⇒ A5
各LLMの回答内容
| LLMの種類 | 回答内容 ※赤いマーカーの部分が誤り。 |
|---|---|
正解! | 28 秒の間、Thought about path in the map 【ポイント】 1. 4 行目 (A4・B4・C4・D4) がすべて壁なので、上下から抜けること ができません。 2. D3 も壁 なので、3 行目で C 列から E列へ直接移動できません。 3. 上記の理由により、いったん上段 (1 行目) へ戻り、右端 (E 列) まで 移動してから、下段 (5 行目) を左に戻る ルートが必要になります。 【順番に並べると】 1. A1 → A2 → A3 2. A3 → B3 → C3 3. C3 → C2 → C1 4. C1 → D1 → E1 5. E1 → E2 → E3 → E4 → E5 6. E5 → D5 → C5 → B5 → A5 すべて「□」のマスだけを通ってゴールまで辿り着くことができます。 |
| このマップで、A1からA5に辿り着くためのルートを考えます。 進行可能な道(□)だけを通るようにします。 【スタートとゴール】 ・スタート: A1 ・ゴール: A5 【移動ルート】 以下の順序で進むと、□(道)だけを通ってA5に辿り着けます。 1. A1 → C1 (右に2マス進む) 2. C1 → C3 (下に2マス進む) 3. C3 → E3 (右に2マス進む) 4. E3 → E5 (下に2マス進む) 【ルート詳細】 A1 → C1 → C3 → E3 → E5 道順としては、右、下、右、下の順番で進むことになります。 これでA1からA5に辿り着くことができます! | |
| A1からA5への最短経路は以下の通りです: A1 → A2 → B3 → C3 → D3 → E3→ E4 → E5 → D5 → C5 → B5 →A5 経路の各ポイントは道(□)のみを通過し、壁(■)は避けています。 | |
| 【問題の理解】 ・マップ:5×5のグリッド状のマップ。’■’が壁、’□‘が道。 ・スタート: A1 ・ゴール: A5 ・経路: 壁を避けてA1からA5へ至る最短経路を求める。 【解法】 この種の経路探索問題は、深さ優先探索や幅優先探索といったアルゴリズムを用いて解くことができます。 今回は、より単純な右か下への移動のみを許すという制約のもと、幅優先探索を用いて解いてみましょう。 幅優先探索とは、・・・ 【今回のマップの場合】 このマップにおいて、右か下への移動のみを許すという制約のもと、幅優先探索を行うと、以下の経路が得られます。 A1 -> B1 -> B2 -> B3-> B4 -> A5 ・・・ 【結論】 このマップにおいて、A1からA5への最短経路は、右か下への移動のみを許す場合、 A1 -> B1-> B2 -> B3 -> B4 -> A5となります。 |
複雑な文章の理解と解釈
長文の読解や、複数の文脈を統合した上での判断も進化しています。これは「遅い思考(Slow Thinking)」の領域に入りつつある部分で、単なるパターンマッチングではなく、文脈を保持しながら解答を生成する能力が向上していることを示しています。
LLMの論理的思考を試す(2) ~倉庫番~
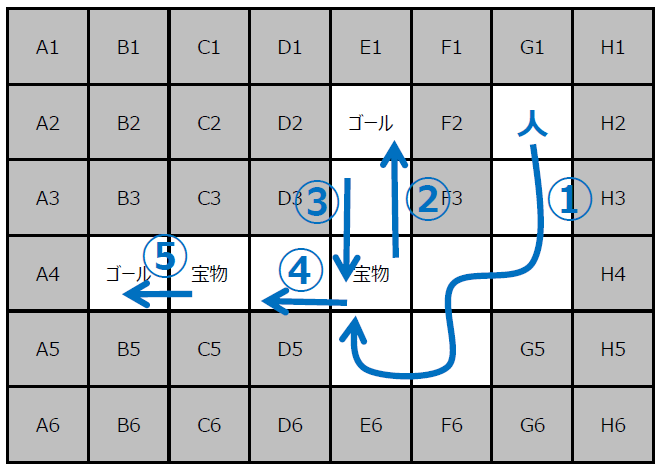
以下に示すマップがあります(座標付き)。
- 人と宝物2つをゴール2か所に運ぶルールは「人は壁を避けて上下左右に移動でき、宝物は人が後ろから押すことで1マスずつ移動させる」とする。
- あなたは、すべての宝物をゴールに運ぶ手順を可能ならば見つけなさい。
- 手順を示すときは、1手ごとに「人の位置」「移動先」「宝物がどう動くか」をテキストで書き出すこと。
- 各手が終わった後のマップ状態(人と宝物の位置)を行ごとに説明し、壁やゴールの位置が変化していないかをチェックすること。
- 「宝物を壁に押しつぶしていないか」「人と宝物が同じマスに重なっていないか」「押す先に別の宝物はいないか」などを自分でチェックして整合性を保つように注意する。
- 最終的に「全宝物がゴール上に配置された」ら成功とみなし、できなければ「解けない」と答え。
マップ(横軸のA,B,C・・・、縦軸の1,2,3・・・は座標)
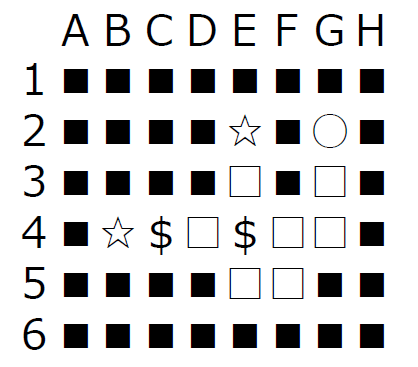
マップの記号の意味
■:壁 / □:道 / ○:人 / $:宝物 / ☆:ゴール
最初にE4にある宝物を左のD4に移動してしまうと手詰まりになる。
各LLMの回答内容
| LLMの種類 | 回答内容 ※赤いマーカーの部分が誤り。 |
|---|---|
正解! | 1m 52sの間、Thought about puzzle solution strategy 以下に、宝物2つ(C4 と E4 の「$」)をそれぞれのゴール(B4 と E2 の「☆」)へ運ぶための手順を示します。 【全体方針】 1.E4 の宝物を上方向(E4 → E3 → E2)へ押し上げ、E2 のゴールに乗せる。そのために、人は E4の真下(E5)から上へ移動して押し上げる。 2,C4 の宝物を左方向(C4 → B4)へ押し、B4のゴールに乗せる。 なお、人が C4 に近づいて「左に押す」ためには D4に回り込む必要があるが、E4 にある宝物を動かさないと D4 に行けないルートが塞がってしまう (※E4 を左へ押してしまうと壁D3があるため詰まる)。 そこで最初に E4 の宝物を上方向に移動させて道を開け、後から C4 の宝物を B4 に押し込みます。 ・・・ よって、両方の宝物をゴールに配置することができました。 以上でパズルは解決です。 |
| この問題は、パズルの一種であり、宝物をゴールに押し込むための手順を見つけることを目的としています。以下の手順で解いていきます。 【初期マップ(状態0)】 人の初期位置:F2 宝物の位置:E4, G4 ゴールの位置:E2, B4 【手順】 1.状態0 → 状態1 人を右へ1マス移動(G2)。宝物は動かない。 2.状態1 → 状態2 人を下へ1マス移動(G3)。宝物は動かない。 3.状態2 → 状態3 人を左へ2マス移動(E3)。宝物は動かない。 ・・・ 【結果】 宝物1:E2(ゴール済み) 宝物2:B4(ゴール済み) すべての宝物がゴールに到達しました。成功です! | |
| 【初期状態】 宝物:(C4)と(E4) ゴール:(B4)と(E2) 人:(G2) このパズルは解けません。 理由: ・宝物(E4)を上のゴール(E2)に押し上げることは可能 ・しかし宝物(C4)は左のゴール(B4)に到達できない ・左側の通路が狭く、宝物を通せない ・上下の迂回路もない | |
| 【問題分析と解法】 この問題は、パズルのような要素を含んだ経路探索問題です。人が壁を避けながら移動し、後ろから宝物を押すというルールの下、 全ての宝物をゴールに 運ぶという目標を達成するための最短経路や 最適な手順を見つける必要があります。 【解法の試行錯誤と結果】 残念ながら、このマップの配置では、全ての宝物をゴールに運ぶことは不可能と判断されました。 【理由】 宝物の配置:2つの宝物が、それぞれ異なるゴールから見て壁で遮られており、直接的にゴールまで押し出すことができません。 経路の制約:人が移動できる経路が限られており、宝物を適切な位置に移動させるための十分なスペースがありません。 【まとめ】 与えられたマップでは、現在のルールと宝物の配置では、全ての宝物をゴールに運ぶことは不可能という結論に至りました。 |
一貫した思考プロセスのシミュレーション
近年のLLMは、思考の過程を分解し、ステップごとに考える(Chain of Thought、ReAct などの手法)ことで、より正確な推論が可能になっています。このような技術を活用することで、人間の問題解決プロセスを模倣しながら、より論理的な解答を生成できるようになってきています。
今後の展望:人間の「代わり」としてのLLM
これまでは「文章要約」「翻訳」「メール下書き」といった 速い思考(Fast Thinking) をサポートするツールとしての利用が主でしたが、今後は 遅い思考(Slow Thinking) を担う場面でも活躍する可能性が高まっています。
例えば
問題の分析・解釈 → 計画の立案 → 解決策の提示 という一連の流れをAIが担うより深い推論を必要とする業務(研究支援、法律判断、戦略立案) において、人間の思考プロセスをシミュレーション自己反省(Self-Reflection)を活用し、誤りを修正しながら思考を進めるようなアプローチの発展こうした方向性が進むことで、単なる「便利なツール」から、「思考のパートナー」へとAIの役割が変化していく可能性が高いですね。
添付された試行結果をもとに、具体的にどのような問題でLLMが「単なる確率的単語選択を超えた」動きを見せたのか、詳しく見ていくとさらに面白そうです!