テキストデータを
AI解析で高度に活用

あらゆるテキストデータを
自然言語理解AIで簡単に解析
Mµgen NLU Optionは、自然言語理解AIにより社内技術文書、コールセンターログ、SNS、アンケート等の様々なデータから、概念・暗黙知の検出や、顧客ニーズを解析し、ウィジェットでわかりやすく表示します。
事前準備、企業内用語辞書、チューニング無しで簡単に解析できます。
埋もれたテキストを
自然言語「理解」AIへ
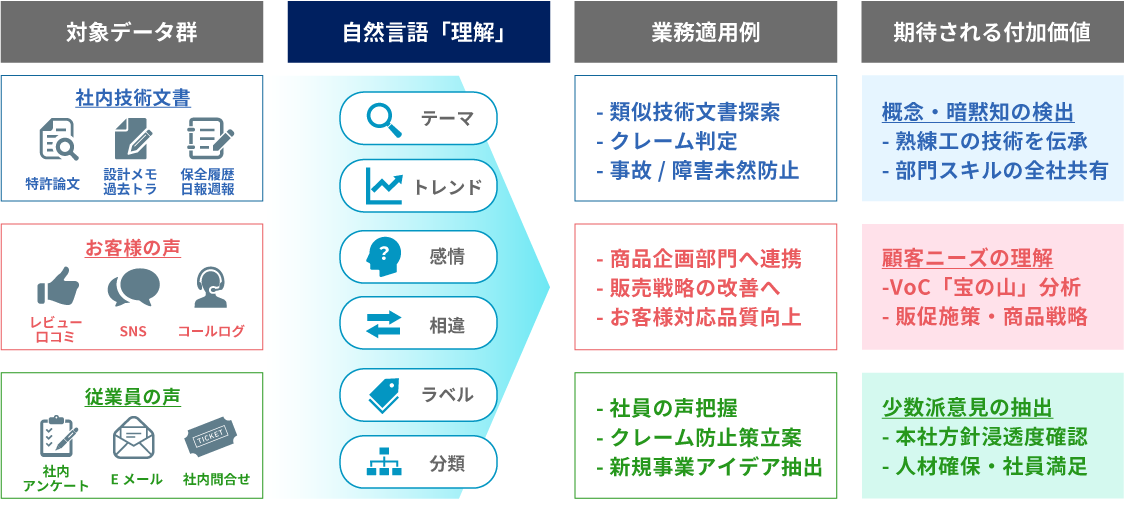
業務で使うデータには、左側にあるような社内技術文書、お客様の声、従業員の声などの自然言語データがたくさんあります。ここにAIによる解析を加えることで、右側にあるようなユースケースでの課題解決にすぐに取り組めるようになります。
| 対象データ群 | 自然言語「理解」 | 適用業務例 | 期待される付加価値 |
|---|---|---|---|
社内技術文書 |
 |
-類似技術文書探索
-クレーム判定 -事故/障害未然防止 |
概念・暗黙知の検出 -熟練工の技術を伝承 -部門スキルの全社共有 |
お客様の声 |
-商品企画部門へ連携 -販売戦略の改善へ -お客様対応品質向上 |
顧客ニーズの理解 -VoC「宝の山」分析 -販促施策・商品戦略 |
|
従業員の声 |
-社員の声把握 -クレーム防止策立案 -新規事業アイデア抽出 |
少数派意見の抽出 -本社方針浸透度確認 -人材確保・社員満足 |
Mµgen NLU Option デモ動画
<NLUデモ動画 1>
<NLUデモ動画 2>
自然言語処理の
ゲームチェンジャー
自然言語「理解」AI
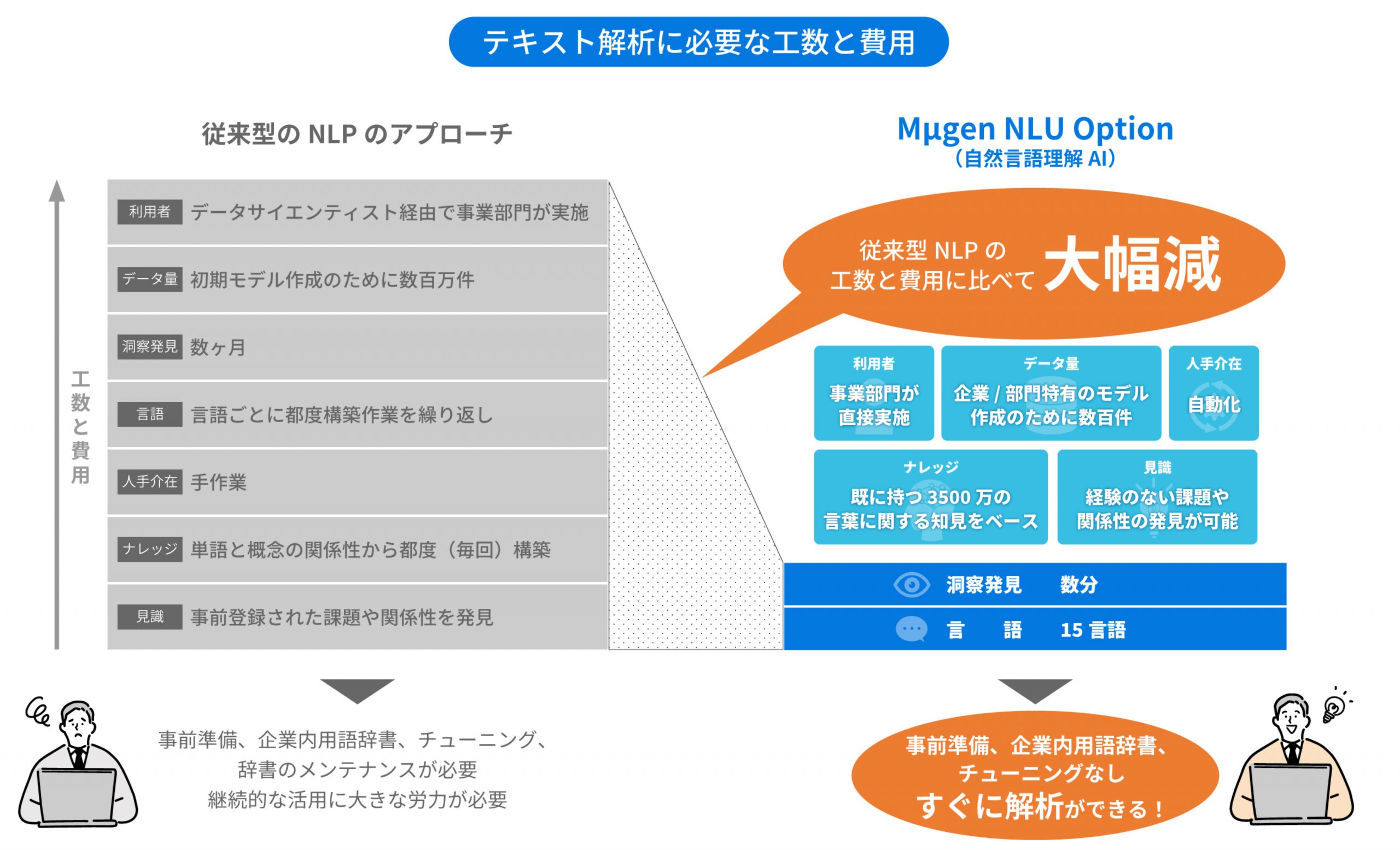
自然言語理解AIの最大の特徴は、辞書なし、チューニングなしで解析できる点です。データ量も数百件程度でも解析することができますので、Mµgenを通じて簡単に自動的に自然言語理解AIを利用することができるようになります。
事前準備なし
企業内用語辞書なし
チューニングなし
Mµgen NLU Option
のウィジェット
Mµgen NLU Optionでは、
以下5種のウィジェットを提供します。
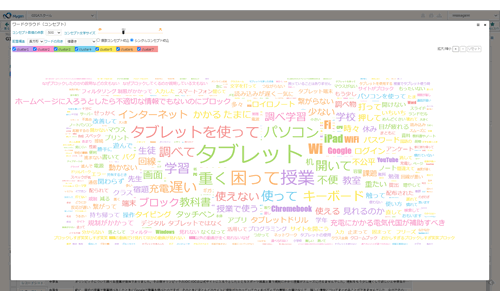
ワードクラウド
ウィジェット
抽出された特徴語をワードクラウド形式で視覚的に確認可能。特徴語を自動分類した色付け、関連する特徴語の傾向を把握できます。
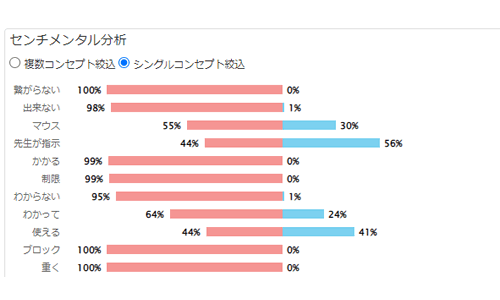
センチメント棒グラフ
ウィジェット
抽出された特徴後の肯定的、否定的な感情動向をグラフで可視化することができます。
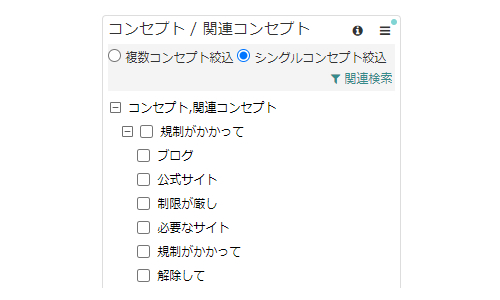
関連コンセプト
ウィジェット
ワードクラウドで選択したコンセプトに関連するコンセプトを表示することができます。
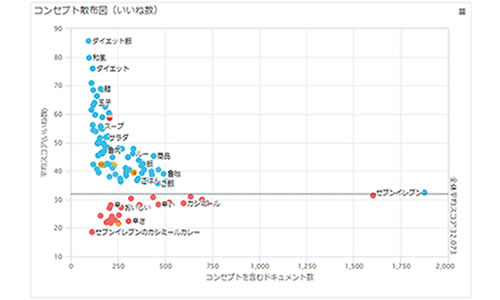
コンセプト散布図
ウィジェット
数値情報のメタデータの値からコンセプトの散らばりを可視化するためのウィジェットです。
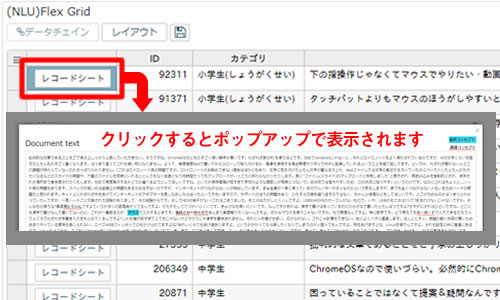
FlexGrid
ウィジェット
取り込んだテキストデータを表形式で表示するためのウィジェットです。コンセプトを検索条件に指定すると、該当するコンセプトがハイライト表示されます。また、本文を表示するレコードシートにもコンセプトがハイライトで表示されます。